Neo4j traverses depths of 1000 levels and beyond at millisecond speed
June 15, 2009 8:50 AM Subscribe
yes that was silly of me, meant to add that but messed up, thanks for the link to the thing itself DU
posted by dabitch at 9:03 AM on June 15, 2009
posted by dabitch at 9:03 AM on June 15, 2009
neo4j is neat, its API feels a bit rough but it's very easy to use and to get going if you have a bit of a graph theory background.
Where it makes sense, the graphing model is actually easier to use than the standard tables and columns approach. Especially in Java, there's a lot of framework and scaffolding just for the mechanism of using SQL or calling stored procedures.
At least with neo4j's API, it's much more straightforward: you create a new node, set whatever attributes you want on it and create (typed) relationships with other nodes you have. That's it! No persistence layer or data access objects to go through or maintain. And because it's a graph model, related nodes are just an edge traversal away (another one method call).
This said, it's more of a niche for where the data naturally fits a graph model, compared with the general fit that relational modeling has become. There's also a lot more experience with with RDBMS in general so I'm cautious on that idea that it will become big.
posted by tksh at 10:28 AM on June 15, 2009 [1 favorite]
Where it makes sense, the graphing model is actually easier to use than the standard tables and columns approach. Especially in Java, there's a lot of framework and scaffolding just for the mechanism of using SQL or calling stored procedures.
At least with neo4j's API, it's much more straightforward: you create a new node, set whatever attributes you want on it and create (typed) relationships with other nodes you have. That's it! No persistence layer or data access objects to go through or maintain. And because it's a graph model, related nodes are just an edge traversal away (another one method call).
This said, it's more of a niche for where the data naturally fits a graph model, compared with the general fit that relational modeling has become. There's also a lot more experience with with RDBMS in general so I'm cautious on that idea that it will become big.
posted by tksh at 10:28 AM on June 15, 2009 [1 favorite]
I was introduced to this idea a few years back, in the context of a few biology researchers thinking about bio-data, how it was deeply inter-related and (in most circumstances) scattered across various and disparate databases. It took me a while to grasp their direction, but the idea was to port or wrap databases into a graph layer which meant that users and AI and data-mining algorithms could explore the mass of inter-connected data with ease.
It was a galvanizing thought. As DU said, the biggest barrier is existing habit. Everyone is used to tables and columns and SQL. There's a lot of experience and expertise tied up in that, regardless of how unnatural expressing some ideas in that form may be. But if object databases are finally getting a foothold, maybe graph databases will.
posted by outlier at 10:30 AM on June 15, 2009
It was a galvanizing thought. As DU said, the biggest barrier is existing habit. Everyone is used to tables and columns and SQL. There's a lot of experience and expertise tied up in that, regardless of how unnatural expressing some ideas in that form may be. But if object databases are finally getting a foothold, maybe graph databases will.
posted by outlier at 10:30 AM on June 15, 2009
First there was the Internet, then the Web, and now the Graph - which Sir Tim labeled (somewhat tongue in cheek) the Giant Global Graph!
Okay, because "WWW" wasn't annoying enough to say, now we can say "GGG?"
Just what we need, a planet of nerds who all sound like Quagmire.
posted by rokusan at 10:46 AM on June 15, 2009
Okay, because "WWW" wasn't annoying enough to say, now we can say "GGG?"
Just what we need, a planet of nerds who all sound like Quagmire.
posted by rokusan at 10:46 AM on June 15, 2009
Wow, neat! Are there any good papers / web pages / blog posts where people talk about using Neo4j on a real problem, with hundreds of megabytes of data, and talks about how it works out? Ie: build a Neo4j database of the relationships of metafilter posters. I'd love to know how it works. Slide 30 of this presentation claims several billion nodes on a single JVM, but I'd like to see more detail.
The other thing that presentation claims (slide 33) is "No O/R impedance mismatch". Which would be awesome, because mapping relational data into objects in Java or Python or Ruby is fundamentally naughty and awful. I've often wondered why people haven't picked up object database research again and made something that worked for journeyman hackers as well as MySQL does.
posted by Nelson at 11:50 AM on June 15, 2009
The other thing that presentation claims (slide 33) is "No O/R impedance mismatch". Which would be awesome, because mapping relational data into objects in Java or Python or Ruby is fundamentally naughty and awful. I've often wondered why people haven't picked up object database research again and made something that worked for journeyman hackers as well as MySQL does.
posted by Nelson at 11:50 AM on June 15, 2009
Everything Old is New Again
Obviously these Ideas have been around for a long time, probably (I would guess) longer then relational databases.
The real problem though is: How do you query? Or rather How do you query in linear time? When you create an Ontology (which is what those are actually called. It would be reassuring if the authors of the software actually knew what they were creating) you're essentially storing a series of logical predicates. An edge relationship in a graph is equivalent to a logical statement like A x B where A and B are objects and x is a relationship.
But a lot of the questions you want to ask about those kinds of graphs are NP-Complete.
The title of this post is "Neo4j traverses depths of 1,000 levels and beyond at millisecond speed" but it doesn't tell you the breadth of the search. For example, let's say it's only traveling along one edge at a time. That means we get 11000 operations. For an example, what if we asked a question like "how many steps backward do we have to go to find out when the mother of the of the mother of ... (and so on) of sue and the mother of the mother of ... (and so on) Jane are the same person?" We only need to follow the "mother" link.
But on the other hand, what if we want to know "how many steps back do you need to go before Sue and Jane share any common ancestor". In that case, at each step there are two branches. That means rather then 11000 you get 21000 steps. 21000 10301 or 1 followed by 301 zeros.
The thing about a relational database is that it makes the sensible queries easy to do. The challenge has never been about storing Ontologies, but rather doing anything with them once you have the data.
--
And of course you can store a graph in a regular relational database as well. All you need is one table for the nodes and one table for the edges. Or you could even just have a single table with A, x, and B but that wouldn't be normalized. It would take literally 10 minutes to implement the storage system for this in a normal relational database system like MySQL, writing a few APIs might take an hour or so.
posted by delmoi at 11:50 AM on June 15, 2009 [3 favorites]
Obviously these Ideas have been around for a long time, probably (I would guess) longer then relational databases.
The real problem though is: How do you query? Or rather How do you query in linear time? When you create an Ontology (which is what those are actually called. It would be reassuring if the authors of the software actually knew what they were creating) you're essentially storing a series of logical predicates. An edge relationship in a graph is equivalent to a logical statement like A x B where A and B are objects and x is a relationship.
But a lot of the questions you want to ask about those kinds of graphs are NP-Complete.
The title of this post is "Neo4j traverses depths of 1,000 levels and beyond at millisecond speed" but it doesn't tell you the breadth of the search. For example, let's say it's only traveling along one edge at a time. That means we get 11000 operations. For an example, what if we asked a question like "how many steps backward do we have to go to find out when the mother of the of the mother of ... (and so on) of sue and the mother of the mother of ... (and so on) Jane are the same person?" We only need to follow the "mother" link.
But on the other hand, what if we want to know "how many steps back do you need to go before Sue and Jane share any common ancestor". In that case, at each step there are two branches. That means rather then 11000 you get 21000 steps. 21000 10301 or 1 followed by 301 zeros.
The thing about a relational database is that it makes the sensible queries easy to do. The challenge has never been about storing Ontologies, but rather doing anything with them once you have the data.
--
And of course you can store a graph in a regular relational database as well. All you need is one table for the nodes and one table for the edges. Or you could even just have a single table with A, x, and B but that wouldn't be normalized. It would take literally 10 minutes to implement the storage system for this in a normal relational database system like MySQL, writing a few APIs might take an hour or so.
posted by delmoi at 11:50 AM on June 15, 2009 [3 favorites]
tksh: "This said, it's more of a niche for where the data naturally fits a graph model, compared with the general fit that relational modeling has become."
There are plenty of places where relational databases aren't a good fit compared to a graph model. Take threaded comment systems for example. The standard way of forcing a tree into a row system is to add a parent field into every row. So every comment is given a parent, or null if it's a top level comment.
I have no idea how you quickly rebuild that query into a tree.
posted by pwnguin at 11:52 AM on June 15, 2009
There are plenty of places where relational databases aren't a good fit compared to a graph model. Take threaded comment systems for example. The standard way of forcing a tree into a row system is to add a parent field into every row. So every comment is given a parent, or null if it's a top level comment.
I have no idea how you quickly rebuild that query into a tree.
posted by pwnguin at 11:52 AM on June 15, 2009
(oops that should say 21000 is 10301 or 1 followed by 301 zeros)
posted by delmoi at 11:54 AM on June 15, 2009
posted by delmoi at 11:54 AM on June 15, 2009
I have no idea how you quickly rebuild that query into a tree.
It's not that hard. If the data is ordered so that children always come after parents, then all you have to do is build a map in memory as you read in the child nodes. Each time you read a child node, you look up the parent in your map and attach it.
If the data isn't ordered that way, you have to create placeholders for nodes haven't been read in yet. But it still isn't very difficult.
posted by delmoi at 11:57 AM on June 15, 2009
It's not that hard. If the data is ordered so that children always come after parents, then all you have to do is build a map in memory as you read in the child nodes. Each time you read a child node, you look up the parent in your map and attach it.
If the data isn't ordered that way, you have to create placeholders for nodes haven't been read in yet. But it still isn't very difficult.
posted by delmoi at 11:57 AM on June 15, 2009
And as I said, every graph can be represented as a relational database, simply by having a "nodes" and "edges" table.
posted by delmoi at 11:58 AM on June 15, 2009
posted by delmoi at 11:58 AM on June 15, 2009
It has a AGPL 3.0 / Commercial license, so be prepared to open up all your code or spend some money.
posted by bottlebrushtree at 12:02 PM on June 15, 2009
posted by bottlebrushtree at 12:02 PM on June 15, 2009
And of course every relational database can be stored as a graph. Each cell in the the database table has a relation to a table, a row, and a column.
So for example a users table with "ID, First name, last name, username, date of birth, signup date"
could be represented by the following predicates:
posted by delmoi at 12:12 PM on June 15, 2009
So for example a users table with "ID, First name, last name, username, date of birth, signup date"
could be represented by the following predicates:
ID is a [User]Graphs and relational databases are isomorphic any graph can be represented as a relational database, and any relational database can be represented as a graph. So a graph storage engine doesn't actually do anything for you that an RDBM doesn't, although in theory it could speed up some algorithms by a constant factor it can't make the order of growth of the any algorithms faster
ID firstname is "Mary"
ID lastname is "Paker"
ID username is "Mparker"
ID was born "5/31/1988"
ID signed up "4/17/2004"
posted by delmoi at 12:12 PM on June 15, 2009
No one is saying that graph databases are the answer to ALL the data problems. As deimol mentions, graphs and tables are two forms of normalization of information.
Graph databases are providing persisting and operation means for the former, as there are trends that are easier implemented with graphs:
- the Giant Global Graph (Berners Lee), LinkedData, RDF and Triples etc.
- Social graphs and operations like shortest paths
- GIS and geodetic models and again shortest path algos
- Semantic trading
- you average domain model
Of course, RDBMS have certainly their place and above all have heavy tooling and experience drawn from 35 years of practice. All honor to that, but for the bleeding edge and increasingly the normal mashup applications out there, the world of data is getting more and more complex, ad hoc, semi-structured and clustered. That is where new kinds of databses - graph databases, key-value stores, DHTs etc etc are starting to kick in.
see http://highscalability.com/neo4j-graph-database-kicks-buttox#comment-5615 for a good discussion of relational vs graph models.
posted by peterneubauer at 12:34 PM on June 15, 2009
Graph databases are providing persisting and operation means for the former, as there are trends that are easier implemented with graphs:
- the Giant Global Graph (Berners Lee), LinkedData, RDF and Triples etc.
- Social graphs and operations like shortest paths
- GIS and geodetic models and again shortest path algos
- Semantic trading
- you average domain model
Of course, RDBMS have certainly their place and above all have heavy tooling and experience drawn from 35 years of practice. All honor to that, but for the bleeding edge and increasingly the normal mashup applications out there, the world of data is getting more and more complex, ad hoc, semi-structured and clustered. That is where new kinds of databses - graph databases, key-value stores, DHTs etc etc are starting to kick in.
see http://highscalability.com/neo4j-graph-database-kicks-buttox#comment-5615 for a good discussion of relational vs graph models.
posted by peterneubauer at 12:34 PM on June 15, 2009
Oracle has hierarchical queries. If only for the classical organisational hierarchy data. I have no idea how that query fares performance-wise compared to a native hierarchical storage.
Hierarchical storage has another modern manifestation in the XML storage, f.i. using Exist, in the so-called XRX architecture (XForms, REST, XQuery).
Never having worked on an XRX system I do wonder what happens to the relations that conceptually exist between data referenced in different XML documents in storage. There's a reason that historical hierarchical databases of yore have been supplanted by the relational databases.
posted by jouke at 12:43 PM on June 15, 2009
Hierarchical storage has another modern manifestation in the XML storage, f.i. using Exist, in the so-called XRX architecture (XForms, REST, XQuery).
Never having worked on an XRX system I do wonder what happens to the relations that conceptually exist between data referenced in different XML documents in storage. There's a reason that historical hierarchical databases of yore have been supplanted by the relational databases.
posted by jouke at 12:43 PM on June 15, 2009
The real problem though is: How do you query?
Wolfram Alpha!
posted by Artw at 12:45 PM on June 15, 2009
Wolfram Alpha!
posted by Artw at 12:45 PM on June 15, 2009
It is impressive to see how things have evolved in this domain. In 1969 the creation of the Internet linked computers together. Then the Web in 1989 linked collections of webpages. More recently, online social initiatives have linked people together with enourmous amount of related data. It's too early to tell if this 'Graph' will really be the next step, but it is indeed interesting and in the right direction.
posted by TMcGregor at 12:47 PM on June 15, 2009
posted by TMcGregor at 12:47 PM on June 15, 2009
Disclaimer: I am part of the Neo4j project.
posted by peterneubauer at 12:48 PM on June 15, 2009 [1 favorite]
posted by peterneubauer at 12:48 PM on June 15, 2009 [1 favorite]
There are plenty of places where relational databases aren't a good fit compared to a graph model.
I'm not convinced overall that there are that many situations where a graph model fits better than a relational model. As delmoi pointed out above, the representations are isomorphic so it's a matter of the characteristics of your model and your design experience that will choose how you store your data. And right now, there is a lot more relational theory experience than graph theory experience or even knowledge.
But yes, when it fits, I find thinking in terms of nodes and edges much more intuitive than trying to construe my mental model to fit tables and columns.
peterneubauer: since we have your attention, can I ask about the neo4j API design? Why is node creation defined only on NeoService? It makes more sense to have the create and delete calls all on Node, e.g.
posted by tksh at 1:27 PM on June 15, 2009
I'm not convinced overall that there are that many situations where a graph model fits better than a relational model. As delmoi pointed out above, the representations are isomorphic so it's a matter of the characteristics of your model and your design experience that will choose how you store your data. And right now, there is a lot more relational theory experience than graph theory experience or even knowledge.
But yes, when it fits, I find thinking in terms of nodes and edges much more intuitive than trying to construe my mental model to fit tables and columns.
peterneubauer: since we have your attention, can I ask about the neo4j API design? Why is node creation defined only on NeoService? It makes more sense to have the create and delete calls all on Node, e.g.
Node.createNode( RelatationType ) that returns Nodeposted by tksh at 1:27 PM on June 15, 2009
pwnguin: "I have no idea how you quickly rebuild that query into a tree."
Jouke mentioned Hierarchical Queries in Oracle. I know that SQL Server has them as well as of 2008 (perhaps 2005 as well), and there were various procs to do the same thing in earlier versions -- I think the T-SQL cookbook has a good example.
posted by boo_radley at 1:34 PM on June 15, 2009
Jouke mentioned Hierarchical Queries in Oracle. I know that SQL Server has them as well as of 2008 (perhaps 2005 as well), and there were various procs to do the same thing in earlier versions -- I think the T-SQL cookbook has a good example.
posted by boo_radley at 1:34 PM on June 15, 2009
Graph databases are providing persisting and operation means for the former, as there are trends that are easier implemented with graphs:
Eh. The representation is the easy part. If you have trouble dealing representing your data, you're probably not that bright. The real question of representation comes in when you're dealing with algorithms, some algorithms will have certain data access pasterns and if you can optimize for those patterns you can speed things up a lot (but never more then the theoretical bounds of the algorithm).
Find some examples where Neo4j is faster then a traditional database design, and it might be interesting.
Right now this sound like a half-baked project from someone who never learned much real CS.
posted by delmoi at 2:00 PM on June 15, 2009
Eh. The representation is the easy part. If you have trouble dealing representing your data, you're probably not that bright. The real question of representation comes in when you're dealing with algorithms, some algorithms will have certain data access pasterns and if you can optimize for those patterns you can speed things up a lot (but never more then the theoretical bounds of the algorithm).
Find some examples where Neo4j is faster then a traditional database design, and it might be interesting.
Right now this sound like a half-baked project from someone who never learned much real CS.
posted by delmoi at 2:00 PM on June 15, 2009
How do you query?
Prolog. At least, I wish.
Or rather How do you query in linear time?
Oh. That.
When you create an Ontology (which is what those are actually called. It would be reassuring if the authors of the software actually knew what they were creating) you're essentially storing a series of logical predicates.
Yes. This is one reason that I sometimes wish I had Prolog instead of SQL.
posted by weston at 4:49 PM on June 15, 2009
Prolog. At least, I wish.
Or rather How do you query in linear time?
Oh. That.
When you create an Ontology (which is what those are actually called. It would be reassuring if the authors of the software actually knew what they were creating) you're essentially storing a series of logical predicates.
Yes. This is one reason that I sometimes wish I had Prolog instead of SQL.
posted by weston at 4:49 PM on June 15, 2009
Find some examples where Neo4j is faster then a traditional database design, and it might be interesting.
I don't think the creator is claiming any major CS breakthroughs here - only to alleviate some traditional pain-points many folks working with real-world data on RDBMSes encounter all the time. Joins perform poorly, and semi-structured data in general is a nightmare to work with.
This is why we see so many DHT and other key-value stores cropping up all over the place. The RDBMs can handle these problems in theory, but in practice they are difficult to scale and easy to get wrong at the worst times.
Something like Neo4j seems like it could strike a nice balance for relational, semi-structured data. Many folks are perfectly happy giving up the schema, but relational integrity is very important to maintain. DHTs scale well, but they make joins even more expensive.
Right now this sound like a half-baked project from someone who never learned much real CS.
This is the exact sort of bile that turns many people off of academia.
posted by anomie at 6:31 PM on June 15, 2009 [2 favorites]
I don't think the creator is claiming any major CS breakthroughs here - only to alleviate some traditional pain-points many folks working with real-world data on RDBMSes encounter all the time. Joins perform poorly, and semi-structured data in general is a nightmare to work with.
This is why we see so many DHT and other key-value stores cropping up all over the place. The RDBMs can handle these problems in theory, but in practice they are difficult to scale and easy to get wrong at the worst times.
Something like Neo4j seems like it could strike a nice balance for relational, semi-structured data. Many folks are perfectly happy giving up the schema, but relational integrity is very important to maintain. DHTs scale well, but they make joins even more expensive.
Right now this sound like a half-baked project from someone who never learned much real CS.
This is the exact sort of bile that turns many people off of academia.
posted by anomie at 6:31 PM on June 15, 2009 [2 favorites]
Hi,
So I'm part of the Neo4j crew and registered just now for this thread. It's running late but hopefully I can answer your questions. If not, I'll be back tomorrow as well and make a second pass.
@Nelson: Are there any good papers / web pages / blog posts where people talk about using Neo4j on a real problem, with hundreds of megabytes of data, and talks about how it works out?
Well, there's a limited customer list over on our corporate site, but unfortunately it doesn't contain any real architectural descriptions. :( Many of our customers deal with several orders of magnitude more than what you're mentioning though so I think you'll be safe. :)
@delmoi: The real problem though is: How do you query? Or rather How do you query in linear time?
Maybe you can look at the query code examples outlined for example here. Does that answer your question about how you query a graph db? We also support declarative pattern-matching queries through SPARQL.
As a side note, queries in "linear time" as you speak about are only usable with trivial data sets. (A query in O(n) is the equivalent of an RDBMS table scan or traversing a linked list, i.e. unusable with real data.) What we want is sub-linear times, like indexed lookups which typically run in O(log n) or better. You seem very interested in theory and throwing around CS lingo so maybe that's interesting for you to know.
@delmoi: When you create an Ontology (which is what those are actually called. It would be reassuring if the authors of the software actually knew what they were creating)
Actually, that's not an ontology. You're confusing meta level and instance level. An ontology is a specification of a conceptualization of a domain, i.e. a meta description of the domain's entities and how they are related. You *can* store that meta layer in a graph db. But in a large majority of the cases what you end up storing in a graph database is the instances.
(Btw, OWL is a language for expressing ontologies, and we support creating a meta model in Neo4j from an OWL file via the owl2neo component. It's unfortunately currently very poorly documented.)
@delmoi: "Neo4j traverses depths of 1,000 levels and beyond at millisecond speed" but it doesn't tell you the breadth of the search
So with *warm caches*, it typically takes 1 microsecond to go from node A to node B via relationship R. I.e. we can traverse 1000 "links" in around 1ms. Obviously exact details are hardware dependent.
@delmoi: And of course you can store a graph in a regular relational database as well.
Yes. Still doesn't mean they can replace graph databases for these use cases. Why?
From a programming model perspective: please see the comments section of the linked article, which discusses this at length.
From a performance perspective: see for example this comment from a crew who tried to implement their graph-heavy system with an RDBMS but ended up having to write their own graph db. I wish you were right, but you're not. You just can't get good enough performance on graph traversals in a RDBMS for a lot of use cases. That's why LinkedIn, Facebook, Google, etc have all decided to NOT use relational dbs *for their graph stuff* and implement their own systems from scratch.
@tksh: Can I ask about the neo4j API design?
For API discussions, please join the mailing list at https://lists.neo4j.org. It's very easy to get our attention!
@delmoi: Eh. The representation is the easy part. If you have trouble dealing representing your data, you're probably not that bright.
Choice of representation is an incredibly important part of creating a usable and maintainable system. Here's a good post that elaborates on this a bit.
@delmoi: Find some examples where Neo4j is faster then a traditional database design, and it might be interesting.
Well, we haven't published any benchmarks at this point. Mainly because we all know that it's so easy to prove anything with benchmarks and we encourage our customers to actually benchmark their specific use cases. But people keep asking for it so maybe we should just throw one together soon.
@delmoi: Right now this sound like a half-baked project from someone who never learned much real CS.
Haha, oh come on. Our team has had more than our fair share of CS, on all levels (BS to PhD). Theory is fun and our CS studies taught us like 10% of what's required to build a real, transactional, enterprise strength graph database. Which is a good start. The other 90%, we picked up working hands on with these issues for the last 9 years.
But rather than trying to convince you it's not a "half-baked projet," why don't you browse around and, even better, actually download and check it out? Would love some feedback on the actual product.
(Man, that was a long comment!)
-EE
posted by emileifrem at 7:02 PM on June 15, 2009 [2 favorites]
So I'm part of the Neo4j crew and registered just now for this thread. It's running late but hopefully I can answer your questions. If not, I'll be back tomorrow as well and make a second pass.
@Nelson: Are there any good papers / web pages / blog posts where people talk about using Neo4j on a real problem, with hundreds of megabytes of data, and talks about how it works out?
Well, there's a limited customer list over on our corporate site, but unfortunately it doesn't contain any real architectural descriptions. :( Many of our customers deal with several orders of magnitude more than what you're mentioning though so I think you'll be safe. :)
@delmoi: The real problem though is: How do you query? Or rather How do you query in linear time?
Maybe you can look at the query code examples outlined for example here. Does that answer your question about how you query a graph db? We also support declarative pattern-matching queries through SPARQL.
As a side note, queries in "linear time" as you speak about are only usable with trivial data sets. (A query in O(n) is the equivalent of an RDBMS table scan or traversing a linked list, i.e. unusable with real data.) What we want is sub-linear times, like indexed lookups which typically run in O(log n) or better. You seem very interested in theory and throwing around CS lingo so maybe that's interesting for you to know.
@delmoi: When you create an Ontology (which is what those are actually called. It would be reassuring if the authors of the software actually knew what they were creating)
Actually, that's not an ontology. You're confusing meta level and instance level. An ontology is a specification of a conceptualization of a domain, i.e. a meta description of the domain's entities and how they are related. You *can* store that meta layer in a graph db. But in a large majority of the cases what you end up storing in a graph database is the instances.
(Btw, OWL is a language for expressing ontologies, and we support creating a meta model in Neo4j from an OWL file via the owl2neo component. It's unfortunately currently very poorly documented.)
@delmoi: "Neo4j traverses depths of 1,000 levels and beyond at millisecond speed" but it doesn't tell you the breadth of the search
So with *warm caches*, it typically takes 1 microsecond to go from node A to node B via relationship R. I.e. we can traverse 1000 "links" in around 1ms. Obviously exact details are hardware dependent.
@delmoi: And of course you can store a graph in a regular relational database as well.
Yes. Still doesn't mean they can replace graph databases for these use cases. Why?
From a programming model perspective: please see the comments section of the linked article, which discusses this at length.
From a performance perspective: see for example this comment from a crew who tried to implement their graph-heavy system with an RDBMS but ended up having to write their own graph db. I wish you were right, but you're not. You just can't get good enough performance on graph traversals in a RDBMS for a lot of use cases. That's why LinkedIn, Facebook, Google, etc have all decided to NOT use relational dbs *for their graph stuff* and implement their own systems from scratch.
@tksh: Can I ask about the neo4j API design?
For API discussions, please join the mailing list at https://lists.neo4j.org. It's very easy to get our attention!
@delmoi: Eh. The representation is the easy part. If you have trouble dealing representing your data, you're probably not that bright.
Choice of representation is an incredibly important part of creating a usable and maintainable system. Here's a good post that elaborates on this a bit.
@delmoi: Find some examples where Neo4j is faster then a traditional database design, and it might be interesting.
Well, we haven't published any benchmarks at this point. Mainly because we all know that it's so easy to prove anything with benchmarks and we encourage our customers to actually benchmark their specific use cases. But people keep asking for it so maybe we should just throw one together soon.
@delmoi: Right now this sound like a half-baked project from someone who never learned much real CS.
Haha, oh come on. Our team has had more than our fair share of CS, on all levels (BS to PhD). Theory is fun and our CS studies taught us like 10% of what's required to build a real, transactional, enterprise strength graph database. Which is a good start. The other 90%, we picked up working hands on with these issues for the last 9 years.
But rather than trying to convince you it's not a "half-baked projet," why don't you browse around and, even better, actually download and check it out? Would love some feedback on the actual product.
(Man, that was a long comment!)
-EE
posted by emileifrem at 7:02 PM on June 15, 2009 [2 favorites]
This is the exact sort of bile that turns many people off of academia.
Well the solution to the problem isn't to reinvent wheels that were studied and given up on decades ago. Sometimes a solution that wasn't practical years ago might become practical later on due to changes in hardware, but to be totally ignorant of what's come before and what was learned isn't exactly very inspiring. I mean, the whole purpose of 'academia' is to learn from what people have done in the past.
There's nothing wrong with doing new things, but doing old things and calling it new is annoying.
posted by delmoi at 2:57 AM on June 16, 2009
Well the solution to the problem isn't to reinvent wheels that were studied and given up on decades ago. Sometimes a solution that wasn't practical years ago might become practical later on due to changes in hardware, but to be totally ignorant of what's come before and what was learned isn't exactly very inspiring. I mean, the whole purpose of 'academia' is to learn from what people have done in the past.
There's nothing wrong with doing new things, but doing old things and calling it new is annoying.
posted by delmoi at 2:57 AM on June 16, 2009
The question was "how do you query in linear time" so the answer can't be "here's how you query in exponential time", which is how long a breadth first search actually takes, which is what you used in your example. (Technically, a BFS is linear in the total number of nodes and edges in the graph, but exponential in terms of the depth of the search and polynomial in terms of the connectedness of the vertexes in the graph)@delmoi: The real problem though is: How do you query? Or rather How do you query in linear time?Maybe you can look at the query code examples outlined for example here. Does that answer your question about how you query a graph db? We also support declarative pattern-matching queries through SPARQL.
I wasn't asking how the query syntax worked, I was asking what the point was in doing queries that would take so long or have such high orders of growth, or if you had an example of some queries that you could do using your system
As a side note, queries in "linear time" as you speak about are only usable with trivial data sets. (A query in O(n) is the equivalent of an RDBMS table scan or traversing a linked list, i.e. unusable with real data.) What we want is sub-linear times, like indexed lookups which typically run in O(log n) or better. You seem very interested in theory and throwing around CS lingo so maybe that's interesting for you to know.Heh, I actually meant constant time or near constant time (such as logarithmic time). I've actually implemented databases that would return results in O(log n) time. I don't mean implemented as in used off the shelf databases and setting up the indexes, but rather writing them from scratch using the red-black tree algorithm in memory mapped files. The reason I did that wasn't because I was having trouble mapping my data to a relational database, but rather because I wanted something that was optimized for exactly what I was doing and would be guaranteed to have smooth performance - never hitting any kind of wall or getting stopped up every once in a while doing something like resizing a hash table.
The problem is, if you tried to run a query like that on data from facebook, it would basically never return unless you set a maximum depth (or unless you happened to luck out and that person was nearby). And if you did set a maximum depth the query would still take forever depending on the connectedness of the graph.
Being able to traverse 1,000 edges in a millisecond is nice, but again, why would you want too? Give me an example of an algorithm or use case where this works better then a RDBMs.
Having implemented non RDBMs storage systems, I know they are out there, but the one I created was very application specific. What are the general use cases for something like this that have a reasonable time complexity with large datasets? Graph reachability isn't a good example because the time complexity is huge.
Actually, that's not an ontology. You're confusing meta level and instance level.No, I'm not. You're the one who's confused here. You could try actually reading the wikipedia article I linked too which lists "Individuals: instances or objects (the basic or "ground level" objects)" as the one of the things that are commonly included in an Ontology (and no, I didn't just change it, you can check the page history :)
posted by delmoi at 3:40 AM on June 16, 2009
@delmoi: I wasn't asking how the query syntax worked, I was asking what the point was in doing queries that would take so long or have such high orders of growth, or if you had an example of some queries that you could do using your system
Ah, ok. So how about this scenario: Let's say we have 1M people, and every person has an avg of 50 friends. Then we want to grab two people randomly and figure out whether they're connected through friends-of-friends. Everyone's supposedly connected by degree six so let's limit the depth to four.
On various randomized graphs with 1M people and 25M friendship relationships we execute that query in an avg of ~2ms with warm caches. That particular pathExists() implementation visits an upper bound of 2*(avg rel)^d/2 where d is depth, so in this case 5000 rels. If our rules of the thumb approximation of 1000 rels/ms holds right the query should always terminate in 5 ms or less. And that's been the upper bound in practice as well.
Neo4j will perform equally well (~2ms) on a graph of 10M people and 250M friendship relationships. And if you can squeeze anywhere near that from a relational database at that scale and beyond, I guarantee you have a job at any large social networking site.
(This is an example from my QCon SF 2008 presentation (on slideshare) but unfortunately I see now that the performance numbers were lost in the Slideshare-ification.)
Incidentally, this is not a theoretical use case. It was given to us as part of a tech evaluation with a large social networking site as a representative example of their usage patterns.
@delmoi: [wikipedia] lists "Individuals: instances or objects (the basic or "ground level" objects)" as the one of the things that are commonly included in an Ontology
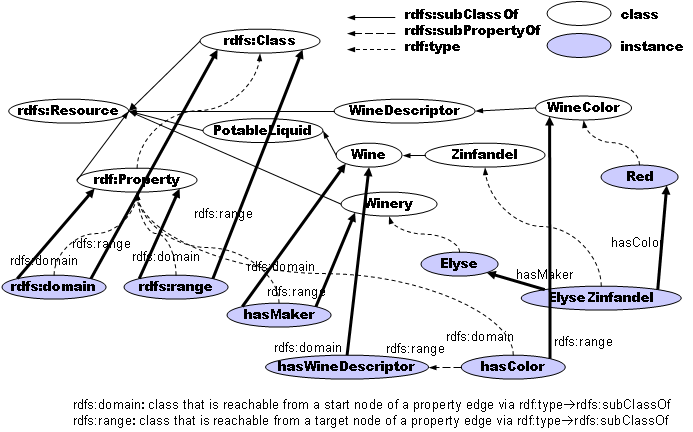
Ah, right, my bad. Ontology is a very overloaded word and I've found that in practice there are two types of ontologies (in CS, not even touching philsophy here obviously): small-scale knowledge-representation ontologies (like for instance the stereotypical wine ontology), where they sometimes add instances as well as types (for example "Elyse Zinfandel" [an instance] intermixed with Zinfandel and Winery [types]). We never work with those as we're not in the knowledge representation business (some of our partners are, and we bring them in for helping our customers with that part if they need it).
The other type is the strict schema ontology, which is what we use sometimes for representing the domain of a system. See an example here.
I tend to call the first "knowledge bases" and the second ontologies as per the famous Noy / McGuinness introductory paper (now at Protege): "An ontology together with a set of individual instances of classes constitutes a knowledge base." That's their definition and they also go on to say "In reality, there is a fine line where the ontology ends and the knowledge base begins." That's the one that has stuck with me.
Back to your original point ("it's an ontology so it'd be reassuring if they called it that"), I've actually found that if I want to scare fellow programmers away from graph databases, a good way is to start speaking about ontologies and knowledge bases. Add some description logic and reification theory to that and we got ourselves a killer image but one that would drive most people away. The semweb crowd likes it so I use it with them. But since my goal is adoption by real-world, industrial applications, I usually stick with the simpler concepts of graph databases. YMMV.
-EE
posted by emileifrem at 6:00 AM on June 16, 2009 [1 favorite]
Ah, ok. So how about this scenario: Let's say we have 1M people, and every person has an avg of 50 friends. Then we want to grab two people randomly and figure out whether they're connected through friends-of-friends. Everyone's supposedly connected by degree six so let's limit the depth to four.
On various randomized graphs with 1M people and 25M friendship relationships we execute that query in an avg of ~2ms with warm caches. That particular pathExists() implementation visits an upper bound of 2*(avg rel)^d/2 where d is depth, so in this case 5000 rels. If our rules of the thumb approximation of 1000 rels/ms holds right the query should always terminate in 5 ms or less. And that's been the upper bound in practice as well.
Neo4j will perform equally well (~2ms) on a graph of 10M people and 250M friendship relationships. And if you can squeeze anywhere near that from a relational database at that scale and beyond, I guarantee you have a job at any large social networking site.
(This is an example from my QCon SF 2008 presentation (on slideshare) but unfortunately I see now that the performance numbers were lost in the Slideshare-ification.)
Incidentally, this is not a theoretical use case. It was given to us as part of a tech evaluation with a large social networking site as a representative example of their usage patterns.
@delmoi: [wikipedia] lists "Individuals: instances or objects (the basic or "ground level" objects)" as the one of the things that are commonly included in an Ontology
Ah, right, my bad. Ontology is a very overloaded word and I've found that in practice there are two types of ontologies (in CS, not even touching philsophy here obviously): small-scale knowledge-representation ontologies (like for instance the stereotypical wine ontology), where they sometimes add instances as well as types (for example "Elyse Zinfandel" [an instance] intermixed with Zinfandel and Winery [types]). We never work with those as we're not in the knowledge representation business (some of our partners are, and we bring them in for helping our customers with that part if they need it).
{kind=link}
The other type is the strict schema ontology, which is what we use sometimes for representing the domain of a system. See an example here.
{kind=link}
I tend to call the first "knowledge bases" and the second ontologies as per the famous Noy / McGuinness introductory paper (now at Protege): "An ontology together with a set of individual instances of classes constitutes a knowledge base." That's their definition and they also go on to say "In reality, there is a fine line where the ontology ends and the knowledge base begins." That's the one that has stuck with me.
Back to your original point ("it's an ontology so it'd be reassuring if they called it that"), I've actually found that if I want to scare fellow programmers away from graph databases, a good way is to start speaking about ontologies and knowledge bases. Add some description logic and reification theory to that and we got ourselves a killer image but one that would drive most people away. The semweb crowd likes it so I use it with them. But since my goal is adoption by real-world, industrial applications, I usually stick with the simpler concepts of graph databases. YMMV.
-EE
posted by emileifrem at 6:00 AM on June 16, 2009 [1 favorite]
On various randomized graphs with 1M people and 25M friendship relationships we execute that query in an avg of ~2ms with warm caches. That particular pathExists() implementation visits an upper bound of 2*(avg rel)^d/2 where d is depth, so in this case 5000 rels.
Sure, but if you wanted a depth of 5 rather then a depth of 4, you would be talking about 250,000 visits or a quarter of a second. And for a depth of 7, you're looking at 12.5 seconds and so on.
You can also do that search with a single SQL query. Lets say you have a users table with people, and a friends table that has a many to many relationship between them (just like the graph example above)
If you want to query out connectedness in 4 steps you can do (something like):
Select user1.id, user2.id from
users as user1
inner join friends on user1.id = friends.in
inner join users as inneruser1 on inneruser1.id = friends.out,
users as user2
inner join friends2 on user2.id = friends2.in
inner join users as inneruser2 on inneruser2.id = friends.out
where inneruser2.id = inneruser1.id and id = @target
I think (but I havn't tried it, obviously) that query should get a list of everyone who is steps away from @target. You might need to tweak it.
Another option would be to get a list of everyone who is two steps away from user1 and 2 and then check for equality in memory. That would require sending a lot more data from the database, so if the DB is on another machine, it would waste bandwidth, but I'm not even sure your solution even works over the network (does it?).
The problem of course is that as you add more and more levels, you need to do more and more joins. But that isn't a real problem because those queries are totally intractable anyway. I guess if you had a really sparse graph (less then 2 connections on average) it might be helpful.
posted by delmoi at 6:23 AM on June 16, 2009
Sure, but if you wanted a depth of 5 rather then a depth of 4, you would be talking about 250,000 visits or a quarter of a second. And for a depth of 7, you're looking at 12.5 seconds and so on.
You can also do that search with a single SQL query. Lets say you have a users table with people, and a friends table that has a many to many relationship between them (just like the graph example above)
If you want to query out connectedness in 4 steps you can do (something like):
Select user1.id, user2.id from
users as user1
inner join friends on user1.id = friends.in
inner join users as inneruser1 on inneruser1.id = friends.out,
users as user2
inner join friends2 on user2.id = friends2.in
inner join users as inneruser2 on inneruser2.id = friends.out
where inneruser2.id = inneruser1.id and id = @target
I think (but I havn't tried it, obviously) that query should get a list of everyone who is steps away from @target. You might need to tweak it.
Another option would be to get a list of everyone who is two steps away from user1 and 2 and then check for equality in memory. That would require sending a lot more data from the database, so if the DB is on another machine, it would waste bandwidth, but I'm not even sure your solution even works over the network (does it?).
The problem of course is that as you add more and more levels, you need to do more and more joins. But that isn't a real problem because those queries are totally intractable anyway. I guess if you had a really sparse graph (less then 2 connections on average) it might be helpful.
posted by delmoi at 6:23 AM on June 16, 2009
that query should get a list of everyone who is steps away from @target.
Er, I mean four steps away, obviously.
posted by delmoi at 6:25 AM on June 16, 2009
Er, I mean four steps away, obviously.
posted by delmoi at 6:25 AM on June 16, 2009
emileifrem: Hi. Sorry to interject but can you check your mefi mail? Upper right corner, tiny envelope icon.
posted by tksh at 6:47 AM on June 16, 2009
posted by tksh at 6:47 AM on June 16, 2009
Hmm, actually I just realized my example above would only find people up to 2 steps apart, not 4. You would need one more level of joins to get to 4 steps.
But the point is if you have a fixed depth, you can do it with a single SQL query.
posted by delmoi at 7:18 AM on June 16, 2009
But the point is if you have a fixed depth, you can do it with a single SQL query.
posted by delmoi at 7:18 AM on June 16, 2009
Thanks for joining us, Emile! Appreciate you coming in and giving more pointers to stuff. Those performance numbers you mention ("randomized graphs with 1M people and 25M friendship relationships") are very interesting. If you have the time and permission to turn that tech evaluation you did into a public white paper, I think a lot of people would learn from it.
delmoi: The problem of course is that as you add more and more levels, you need to do more and more joins. But that isn't a real problem because those queries are totally intractable anyway.
I think the promise of Neo4j is that in their representation, those queries are not intractable. Sure you can model a graph in a relational database, but as you contemplate inner joining your giant Friendships table with itself 4 times to work on the set of people 4 links away from someone, you realize it's going to not work very well. That's why every social network site I know (the big ones) either avoid doing large graph calculations on their network or else build custom datastores.
I'm excited to see that Neo4j is trying to provide a datastore better suited for this task. And respectfully, delmoi, despite your awesome skillz with red-black trees and mmap() I suggest it might take you a few weeks to evaluate whether Neo4j has accomplished something new and useful or not. I don't have the time or interest to do that evaluation myself, so I don't know how well it works, but that's hardly a reason for me to dismiss it out of hand on Metafilter.
posted by Nelson at 8:53 AM on June 16, 2009
delmoi: The problem of course is that as you add more and more levels, you need to do more and more joins. But that isn't a real problem because those queries are totally intractable anyway.
I think the promise of Neo4j is that in their representation, those queries are not intractable. Sure you can model a graph in a relational database, but as you contemplate inner joining your giant Friendships table with itself 4 times to work on the set of people 4 links away from someone, you realize it's going to not work very well. That's why every social network site I know (the big ones) either avoid doing large graph calculations on their network or else build custom datastores.
I'm excited to see that Neo4j is trying to provide a datastore better suited for this task. And respectfully, delmoi, despite your awesome skillz with red-black trees and mmap() I suggest it might take you a few weeks to evaluate whether Neo4j has accomplished something new and useful or not. I don't have the time or interest to do that evaluation myself, so I don't know how well it works, but that's hardly a reason for me to dismiss it out of hand on Metafilter.
posted by Nelson at 8:53 AM on June 16, 2009
I think the promise of Neo4j is that in their representation, those queries are not intractable.
Uh no, the problems are intractable no mater how you represent your data, that's just a mathematical fact. emileifrem confirmed this when he gave the time complexity of his Breadth First search algorithm, by the way.
but as you contemplate inner joining your giant Friendships table with itself 4 times to work on the set of people 4 links away from someone, you realize it's going to not work very well.
Of course not, but the same is true of a Breadth First search in any representation. The point I was making that the graph database doesn't solve the "you need lots of queries to do this" because it can actually be done with just one query. If you can eliminate extra seperate queries you can really boost performance, but that's not happened here.
I suggest it might take you a few weeks to evaluate whether Neo4j has accomplished something new and useful or not.
I actually have better things to do with my time. If they've got a better use case that shows Something you can't do in a relational database easily or quickly, then it would be more intresting.
I'm hardly a huge fanboi for relational databases, but it would be helpful if you want to do something to new to have a clear idea of what drawback you're correcting, preferably with a real world use case.
posted by delmoi at 2:05 PM on June 16, 2009
Uh no, the problems are intractable no mater how you represent your data, that's just a mathematical fact. emileifrem confirmed this when he gave the time complexity of his Breadth First search algorithm, by the way.
but as you contemplate inner joining your giant Friendships table with itself 4 times to work on the set of people 4 links away from someone, you realize it's going to not work very well.
Of course not, but the same is true of a Breadth First search in any representation. The point I was making that the graph database doesn't solve the "you need lots of queries to do this" because it can actually be done with just one query. If you can eliminate extra seperate queries you can really boost performance, but that's not happened here.
I suggest it might take you a few weeks to evaluate whether Neo4j has accomplished something new and useful or not.
I actually have better things to do with my time. If they've got a better use case that shows Something you can't do in a relational database easily or quickly, then it would be more intresting.
I'm hardly a huge fanboi for relational databases, but it would be helpful if you want to do something to new to have a clear idea of what drawback you're correcting, preferably with a real world use case.
posted by delmoi at 2:05 PM on June 16, 2009
Sorry to drop by so late, but running very low on cycles here. Some quick comments:
@Nelson: Thanks for your kind comments. I agree we should take time to make a white paper out of that PoC. So much to do and so little time. :)
@delmoi: I think the step-by-step evolution of your SQL is converging on one of my two main points => the difficulty of writing a query like this in SQL. I'd say you're probably 50 lines short of a query that returns true/false if an arbitrary-length path exists between two persons, parameterized with max depth, taking into account directed relationships. Developing it is a nightmare and maintaining it even worse.
My second point is that the performance will be horrible. With the data set size I quoted (10M persons, 250M follows rels) I think a query with depth 4 will probably execute in hours.
There's a reason why all the big guys have implemented their own data stores for these operations. And it's not because they don't know their RDBMS-fu. They certainly have both the money and the know-how to poor the best the world has to offer in terms of RDBMS design & optimization into their solutions. No, it's because they've pushed and pushed and pushed their relational dbs to the limit and beyond and in pure desperation had to implement their own brand new system from scratch in order to solve their real-world problems.
When we look at those problems, that they can't solve using an RDBMS, we see that a graph db handles them really well. Not in perpetuity. But up to the limits that make sense for them (they don't want to check depth 6 because then we might as well just hard code it to constantly return true). And a graph db solves them well enough that you can use an off-the-shelf Neo4j to run them. In production. I'm not sure if it can be clearer or more real world than that? (And we haven't even discussed all the development-time benefits of a graph db in terms of schema free modeling and little impedance mismatch, etc.)
But if you can write a query as per the above which executes anywhere near Neo4j's 2ms, actually even if you get it below one minute, I would *love* to see your SQL and E/R model. I'm not saying this rhetorically, I'm very serious: If you think you can do it, please do try it out and let me know (first name @ neotechnology.com) how it worked out.
If Neo4j isn't at least 1 000 000 times faster then I'll owe you a beer. :)
-EE
posted by emileifrem at 6:01 PM on June 17, 2009
@Nelson: Thanks for your kind comments. I agree we should take time to make a white paper out of that PoC. So much to do and so little time. :)
@delmoi: I think the step-by-step evolution of your SQL is converging on one of my two main points => the difficulty of writing a query like this in SQL. I'd say you're probably 50 lines short of a query that returns true/false if an arbitrary-length path exists between two persons, parameterized with max depth, taking into account directed relationships. Developing it is a nightmare and maintaining it even worse.
My second point is that the performance will be horrible. With the data set size I quoted (10M persons, 250M follows rels) I think a query with depth 4 will probably execute in hours.
There's a reason why all the big guys have implemented their own data stores for these operations. And it's not because they don't know their RDBMS-fu. They certainly have both the money and the know-how to poor the best the world has to offer in terms of RDBMS design & optimization into their solutions. No, it's because they've pushed and pushed and pushed their relational dbs to the limit and beyond and in pure desperation had to implement their own brand new system from scratch in order to solve their real-world problems.
When we look at those problems, that they can't solve using an RDBMS, we see that a graph db handles them really well. Not in perpetuity. But up to the limits that make sense for them (they don't want to check depth 6 because then we might as well just hard code it to constantly return true). And a graph db solves them well enough that you can use an off-the-shelf Neo4j to run them. In production. I'm not sure if it can be clearer or more real world than that? (And we haven't even discussed all the development-time benefits of a graph db in terms of schema free modeling and little impedance mismatch, etc.)
But if you can write a query as per the above which executes anywhere near Neo4j's 2ms, actually even if you get it below one minute, I would *love* to see your SQL and E/R model. I'm not saying this rhetorically, I'm very serious: If you think you can do it, please do try it out and let me know (first name @ neotechnology.com) how it worked out.
If Neo4j isn't at least 1 000 000 times faster then I'll owe you a beer. :)
-EE
posted by emileifrem at 6:01 PM on June 17, 2009
« Older "Nowadays a chantey is worth 1000 songs on an... | Bank insider steals 200 billion Newer »
This thread has been archived and is closed to new comments
(And why the FPP link to talk about the thing rather than the thing itself?)
posted by DU at 9:02 AM on June 15, 2009