humans don’t behave based on administrative units
August 16, 2019 9:23 AM Subscribe
"Even though there are different place associations that probably mean more to you as an individual, such as a neighborhood, street, or the block you live on, the zip code is, in many organizations, the geographic unit of choice. [...] The problem is that zip codes are not a good representation of real human behavior, and when used in data analysis, often mask real, underlying insights, and may ultimately lead to bad outcomes." Stop Using Zip Codes for Geospatial Analysis
"don't use zipcodes for geospatial analysis" -a company selling a geospatial analysis platform
posted by Kwine at 9:56 AM on August 16, 2019 [21 favorites]
posted by Kwine at 9:56 AM on August 16, 2019 [21 favorites]
TL;DR: grouping populations into geospatial quadrants that accurately reflect common underlying socioeconomic circumstances is hard and we have no solution for it, but don't use zipcodes.
posted by grumpybear69 at 9:58 AM on August 16, 2019 [9 favorites]
posted by grumpybear69 at 9:58 AM on August 16, 2019 [9 favorites]
Using ZCTAs is actually not that bad: there's only a 1.4% error rate.
posted by rossmeissl at 10:03 AM on August 16, 2019 [2 favorites]
posted by rossmeissl at 10:03 AM on August 16, 2019 [2 favorites]
I did a deep dive on this last year after finding the perfect example; the River Oaks neighborhood in Houston. It's a famously wealthy area, zip code 77019. But that zip code is shared with a neighborhood to the east which is significantly less wealthy. So if you do pretty much any demographics by zip code, you get confused. (This is a different problem from the one rossmeissl's link talks about.)
The right answer for many applications, as this article notes, is census tracts named by FIPS codes. These are designed by the census to be demographically consistent; River Oaks is pretty perfectly named by the combination of 4112 and 4114 (both in 48201, Harris County Texas). Unfortunately census tracts are not well known outside social science circles, so people keep using zip codes instead because they don't know better. They're also a little tricky to use since they change frequently (every census?) although zip codes are not entirely stable either.
Census Reporter is a good web tool for exploring data by census tract. Here's 4112 in River Oaks.
posted by Nelson at 10:04 AM on August 16, 2019 [20 favorites]
The right answer for many applications, as this article notes, is census tracts named by FIPS codes. These are designed by the census to be demographically consistent; River Oaks is pretty perfectly named by the combination of 4112 and 4114 (both in 48201, Harris County Texas). Unfortunately census tracts are not well known outside social science circles, so people keep using zip codes instead because they don't know better. They're also a little tricky to use since they change frequently (every census?) although zip codes are not entirely stable either.
Census Reporter is a good web tool for exploring data by census tract. Here's 4112 in River Oaks.
posted by Nelson at 10:04 AM on August 16, 2019 [20 favorites]
Great in theory, but problematic on a couple fronts:
1. the lack of homogeneity can sometimes be a boon for city planners:
2. Like cameras (or any other gear/ tool), the best data you have is often the data you have now. If the latest data is provided in zip code blocks to anonymize individuals in the group, use that data. On the city/ urban/ regional planner side, getting point data can be expensive, complicated, or not desired, depending on your agency and your desired data set. You can't roll your own aggregation from point data if you don't have point data. Sure, if you do, don't default to ZIP codes, agreed on that.
3. "don't use zipcodes for geospatial analysis" -a company selling a geospatial analysis platform -- yep, that:
4. Bonus note: city boundaries are just as arbitrary as ZIP codes, and census blocks for that matter, and none of it matches up. I think Counties might be a pretty reliable boundary folks agree upon, but if not, you have to look to U.S. state boundaries to find broad agreement.
Cities grow, urban areas expand, so you may not even be able to match city boundary data from year-to-year, if you're looking to describe annual changes apples-to-apples.
posted by filthy light thief at 10:04 AM on August 16, 2019 [9 favorites]
1. the lack of homogeneity can sometimes be a boon for city planners:
What we can see is that 12 month median household income in this single zip code (75206) ranges from $9,700 to $227,000 when we look at block groups that completely or partially fall within this single ZIP Code, which the Census lists as having a median household income of $63,392.That's not necessarily a flaw. In fact this sounds like a diverse community, which from a planning standpoint, is often a desired outcome for a community or neighborhood.
2. Like cameras (or any other gear/ tool), the best data you have is often the data you have now. If the latest data is provided in zip code blocks to anonymize individuals in the group, use that data. On the city/ urban/ regional planner side, getting point data can be expensive, complicated, or not desired, depending on your agency and your desired data set. You can't roll your own aggregation from point data if you don't have point data. Sure, if you do, don't default to ZIP codes, agreed on that.
3. "don't use zipcodes for geospatial analysis" -a company selling a geospatial analysis platform -- yep, that:
To perform this analysis for the entire United States, I used CARTO and it’s notebook extension CARTOframes to pull in census data for Census Block Groups and Census ZCTA areas, which are stored in CARTO.Sorry, gotta echo Kwine on this. This reads as more of a product pitch than an actual solution to a problem.
4. Bonus note: city boundaries are just as arbitrary as ZIP codes, and census blocks for that matter, and none of it matches up. I think Counties might be a pretty reliable boundary folks agree upon, but if not, you have to look to U.S. state boundaries to find broad agreement.
Cities grow, urban areas expand, so you may not even be able to match city boundary data from year-to-year, if you're looking to describe annual changes apples-to-apples.
posted by filthy light thief at 10:04 AM on August 16, 2019 [9 favorites]
Crap as they are, it would be nice to be in a country with a free location database. Canada doesn't, the UK didn't for a while then did but probably doesn't any more, and the less said about Ireland …
Also, Zip codes/postcodes/postal codes exist for the convenience of delivering letters. Not for anything else.
posted by scruss at 10:06 AM on August 16, 2019 [1 favorite]
Also, Zip codes/postcodes/postal codes exist for the convenience of delivering letters. Not for anything else.
posted by scruss at 10:06 AM on August 16, 2019 [1 favorite]
This all depends almost entirely upon what you’re doing the analysis for. The why determines the how.
posted by aramaic at 10:07 AM on August 16, 2019 [3 favorites]
posted by aramaic at 10:07 AM on August 16, 2019 [3 favorites]
"don't use zipcodes for geospatial analysis" -a company selling a geospatial analysis platform
No company has ever sold a product for good reason.
posted by kenko at 10:07 AM on August 16, 2019
No company has ever sold a product for good reason.
posted by kenko at 10:07 AM on August 16, 2019
The claim this article is Carto's dastardly plan to sell spatial data tools is ridiculous. First, Carto is simply right about the shortcomings of zip codes and ZCTAs. Second, using some alternative like Census Tract polygons or H3 polygons isn't any harder from a software point of view than using ZCTA polygons; using the right spatial division doesn't require any more than using the wrong one. Third, the fine article we're discussing here recommends many third party and open source options for working with various spatial division choices. It's not like a giant ad for Carto.
posted by Nelson at 10:08 AM on August 16, 2019 [14 favorites]
posted by Nelson at 10:08 AM on August 16, 2019 [14 favorites]
This reads as more of a product pitch than an actual solution to a problem.
Yeah, I know, this is a bit more Pepsi Blue (Mapsi Blue?) than I would have liked, but there are so many bad and misleading maps out there, I found this to be a pretty solid explanation of why zip codes aren't always great for data analysis. For what it's worth, I'm a cartographer and have never used that company.
posted by everybody had matching towels at 10:09 AM on August 16, 2019 [5 favorites]
Yeah, I know, this is a bit more Pepsi Blue (Mapsi Blue?) than I would have liked, but there are so many bad and misleading maps out there, I found this to be a pretty solid explanation of why zip codes aren't always great for data analysis. For what it's worth, I'm a cartographer and have never used that company.
posted by everybody had matching towels at 10:09 AM on August 16, 2019 [5 favorites]
In fact this sounds like a diverse community,
It might be, or it might be a group of distinct, non-diverse communities.
posted by kenko at 10:09 AM on August 16, 2019 [13 favorites]
It might be, or it might be a group of distinct, non-diverse communities.
posted by kenko at 10:09 AM on August 16, 2019 [13 favorites]
Also -- humans don't aggregate cleanly on any axis or in any grouping, so include caveats in your reports, and consider how much precision you use in reporting statistics (US National Library of Medicine, National Institutes of Health, but the message still applies).
Just because your software or equation can report in precision out to the thousands place doesn't mean it makes sense to do so. Does it make sense to say "15.327 people will travel from this block to that new shopping center per day when it is completed, resulting in 12.732 additional vehicles on this road every day"? Particularly when you're using aggregated data and not even a travel survey. Even if the software spits that out, the humans reporting it should then say "approximately 15 people are expected to travel from A to B, resulting in approximately 12 additional vehicles traveling on this road every day," or you may want to even "fuzz" it further, giving ranges of values for people and vehicles.
posted by filthy light thief at 10:13 AM on August 16, 2019 [4 favorites]
Just because your software or equation can report in precision out to the thousands place doesn't mean it makes sense to do so. Does it make sense to say "15.327 people will travel from this block to that new shopping center per day when it is completed, resulting in 12.732 additional vehicles on this road every day"? Particularly when you're using aggregated data and not even a travel survey. Even if the software spits that out, the humans reporting it should then say "approximately 15 people are expected to travel from A to B, resulting in approximately 12 additional vehicles traveling on this road every day," or you may want to even "fuzz" it further, giving ranges of values for people and vehicles.
posted by filthy light thief at 10:13 AM on August 16, 2019 [4 favorites]
Huh. One of the most income-unequal zip codes in the US is 98105 in Seattle, next door to my home zip of 98115... which, yeah, that tracks.
posted by sugar and confetti at 10:17 AM on August 16, 2019
posted by sugar and confetti at 10:17 AM on August 16, 2019
census blocks for that matter, and none of it matches up
I disagree, sort of! Census blocks, block groups, tracts, etc. all nest into each other, and are coded as such. When blocks split, their code number makes it clear that it was split, and which block was split. Yes, they aren't perfectly stable over the decades, but you can easily and consistently figure out where and how the changes were made. Zip Codes/ZCTAs change often and don't aggregate or nest to anything (this is one of the mapping hills I will die on, the other being using facebook likes as a unit of measure for anything).
posted by everybody had matching towels at 10:21 AM on August 16, 2019 [12 favorites]
I disagree, sort of! Census blocks, block groups, tracts, etc. all nest into each other, and are coded as such. When blocks split, their code number makes it clear that it was split, and which block was split. Yes, they aren't perfectly stable over the decades, but you can easily and consistently figure out where and how the changes were made. Zip Codes/ZCTAs change often and don't aggregate or nest to anything (this is one of the mapping hills I will die on, the other being using facebook likes as a unit of measure for anything).
posted by everybody had matching towels at 10:21 AM on August 16, 2019 [12 favorites]
sugar and confetti writes: One of the most income-unequal zip codes in the US is 98105 in Seattle, next door to my home zip of 98115
We must be neighbors. Used to live in the former zip, now in the latter.
posted by Araucaria at 10:54 AM on August 16, 2019
We must be neighbors. Used to live in the former zip, now in the latter.
posted by Araucaria at 10:54 AM on August 16, 2019
Second, using some alternative like Census Tract polygons or H3 polygons isn't any harder from a software point of view than using ZCTA polygons; using the right spatial division doesn't require any more than using the wrong one.
It's not any harder on a musical point of view or a culinary point of view, either. But those points of view are all irrelevant when the actual problem is the data availability point of view. Quick, think of your zip code. Now think of your census tract number. Now, your home latitude and longitude. Now, your Uber H3 code. I suspect one of these is about a million times easier. And a lot of data is gathered from people rather than from computer systems. A zip code is also information-dense; you only need to enter five numbers to get what is typically a relatively good sense of where something is.
Don't get me wrong -- if you have point data, census tracts are a lot better than ZCTAs. Although they're not perfect; no geography is and it depends on the problem. Sometimes, an administrative geography like a city boundary is the best if you're concerned with what that administration is doing (never mind that city boundaries can be appalling; they're patchy and jagged and can be full of holes. I once compared the boundary of Bakersfield to a vomit splatter.) If you work with employment, you find that census tracts -- which are drawn to contain a similar small number of residents -- can have massive areas with hundreds of thousands of jobs in a single tract, because nobody lives there, it's a gigantic industrial area.
The system I like the best, having worked in a few places, is the current Australian system where there are a series of 4 levels of nesting census geographies that go from 400 people (~US census block group level) up to the low hundreds of thousands.
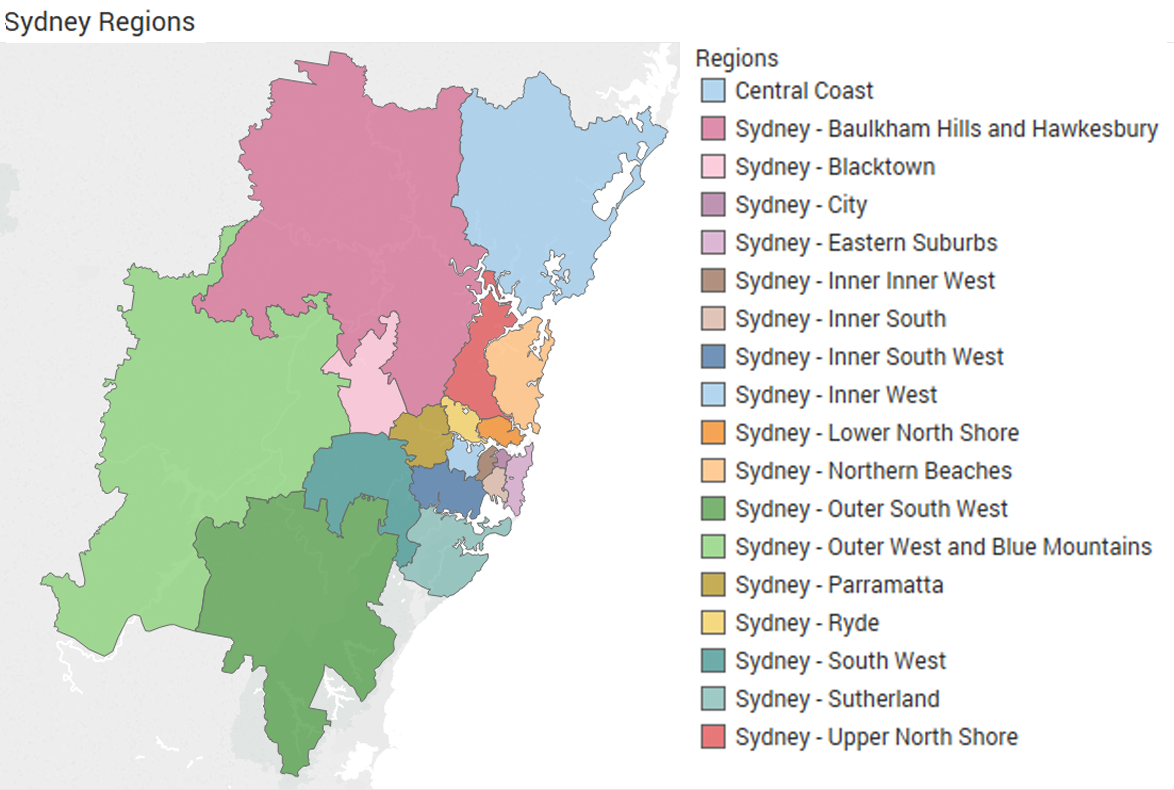
In the US, there's not a geography between census tract and county*, and the latter is problematic. For instance, metro New York (the MSA) is around 20 counties, and the central ones are useful (the five boroughs). Metro Chicago is 14, which sounds similar in scale, but more than half the population including the entire city is in Cook County. Metro LA is only two counties, or if you use greater LA you get up to five, but you are now all the way to Nevada and Arizona and include an area of desert the size of Latvia. But Sydney has 15 SA4 subgeographies, each containing 4-12% of the population; these are broken up into 2 to 5 SA3 geographies each, so there's 47 SA3s. And so on down to SA2 and SA1 level. (And they're all numerically coded -- SA4 number 125 (Sydney-Paramatta) contains SA3s 12501, 12502, 12503 and 12504.) It's heavenly.
* PUMAs are useful, since they're aggregations of tracts and of similar size (100K people). But they aren't widely used yet, and they have issues where they cross county boundaries, which can cause problems.
posted by Homeboy Trouble at 11:17 AM on August 16, 2019 [8 favorites]
It's not any harder on a musical point of view or a culinary point of view, either. But those points of view are all irrelevant when the actual problem is the data availability point of view. Quick, think of your zip code. Now think of your census tract number. Now, your home latitude and longitude. Now, your Uber H3 code. I suspect one of these is about a million times easier. And a lot of data is gathered from people rather than from computer systems. A zip code is also information-dense; you only need to enter five numbers to get what is typically a relatively good sense of where something is.
Don't get me wrong -- if you have point data, census tracts are a lot better than ZCTAs. Although they're not perfect; no geography is and it depends on the problem. Sometimes, an administrative geography like a city boundary is the best if you're concerned with what that administration is doing (never mind that city boundaries can be appalling; they're patchy and jagged and can be full of holes. I once compared the boundary of Bakersfield to a vomit splatter.) If you work with employment, you find that census tracts -- which are drawn to contain a similar small number of residents -- can have massive areas with hundreds of thousands of jobs in a single tract, because nobody lives there, it's a gigantic industrial area.
The system I like the best, having worked in a few places, is the current Australian system where there are a series of 4 levels of nesting census geographies that go from 400 people (~US census block group level) up to the low hundreds of thousands.
In the US, there's not a geography between census tract and county*, and the latter is problematic. For instance, metro New York (the MSA) is around 20 counties, and the central ones are useful (the five boroughs). Metro Chicago is 14, which sounds similar in scale, but more than half the population including the entire city is in Cook County. Metro LA is only two counties, or if you use greater LA you get up to five, but you are now all the way to Nevada and Arizona and include an area of desert the size of Latvia. But Sydney has 15 SA4 subgeographies, each containing 4-12% of the population; these are broken up into 2 to 5 SA3 geographies each, so there's 47 SA3s. And so on down to SA2 and SA1 level. (And they're all numerically coded -- SA4 number 125 (Sydney-Paramatta) contains SA3s 12501, 12502, 12503 and 12504.) It's heavenly.
{kind=link}
* PUMAs are useful, since they're aggregations of tracts and of similar size (100K people). But they aren't widely used yet, and they have issues where they cross county boundaries, which can cause problems.
posted by Homeboy Trouble at 11:17 AM on August 16, 2019 [8 favorites]
I find it strange that the article calls out Canadian postal codes as corresponding to odd areas. In cities, postal codes generally map to either a single large building (office tower, apartment tower, etc) or to one side of one city block of smaller buildings. Small towns without home mail delivery generally have a single postal code for the town. Given that, individual postal codes generally cover an area small enough to correspond to fairly homogeneous groups of people (or businesses). And because there is some structure to them, they can be rolled up, as well.
There are obviously other ways to divide people and area up -- in my work, we mostly use hexagons that are 25 square kilometers along with named communities that don't have a well-defined shape to them -- but those methods aren't without their own failings.
posted by jacquilynne at 11:40 AM on August 16, 2019
There are obviously other ways to divide people and area up -- in my work, we mostly use hexagons that are 25 square kilometers along with named communities that don't have a well-defined shape to them -- but those methods aren't without their own failings.
posted by jacquilynne at 11:40 AM on August 16, 2019
There's definitely a problem that there's not a sensible, standard spatial unit of analysis; or rather, that there are so many ones of 'em we get into the XKCD "standards" thing. Census tracts make a lot more sense given how the nest, but -
The trouble with this, for me, comes down to the fact that data analysis and visualization and mapping often relies on data generated by some other process. So you use what you have. I work in public health, and a lot of the health data we can get our hands on are anonymized; dive into the individual records and you have somebody's ZIP code, not their address; you can aggregate up, but ZIP is your unit because the original piece of data was, like, a billing or hospital admissions form that included somebody's address. And when it was anonymized, ZIP remained.
The issue of ZIPs not adequately representing human behavior or consistent demographics - well, that's a probem of any spatial unit, isn't it? There will always be variation within as well as between - a good analyst knows the underlying geography well enough to know these issues, to know a population well enough to know what's hidden by layers of abstraction. Knows the limits of the data.
posted by entropone at 11:51 AM on August 16, 2019 [4 favorites]
The trouble with this, for me, comes down to the fact that data analysis and visualization and mapping often relies on data generated by some other process. So you use what you have. I work in public health, and a lot of the health data we can get our hands on are anonymized; dive into the individual records and you have somebody's ZIP code, not their address; you can aggregate up, but ZIP is your unit because the original piece of data was, like, a billing or hospital admissions form that included somebody's address. And when it was anonymized, ZIP remained.
The issue of ZIPs not adequately representing human behavior or consistent demographics - well, that's a probem of any spatial unit, isn't it? There will always be variation within as well as between - a good analyst knows the underlying geography well enough to know these issues, to know a population well enough to know what's hidden by layers of abstraction. Knows the limits of the data.
posted by entropone at 11:51 AM on August 16, 2019 [4 favorites]
Census block group, and block group compared to County or Parish, is recommended by EPA for land-based environmental justice analyses.
The census doesn t automatically generate income or percent poverty for block group, but it s easy to get, say, a set of all block groups that have a higher percentage of Native American population than their respective parishes. Bullard and Wright have compared this method to other geo-methods and find it acceptable.
Justicemap.org has the ACS 2016 in slippy map format, which also enables you to conduct the classic "3 mile radius" analysis for air-based impacts.
posted by eustatic at 12:13 PM on August 16, 2019 [1 favorite]
The census doesn t automatically generate income or percent poverty for block group, but it s easy to get, say, a set of all block groups that have a higher percentage of Native American population than their respective parishes. Bullard and Wright have compared this method to other geo-methods and find it acceptable.
Justicemap.org has the ACS 2016 in slippy map format, which also enables you to conduct the classic "3 mile radius" analysis for air-based impacts.
posted by eustatic at 12:13 PM on August 16, 2019 [1 favorite]
"city boundaries are just as arbitrary as ZIP codes"
From a certain perspective, all human geography is pretty arbitrary. :)
posted by kevinbelt at 12:20 PM on August 16, 2019 [1 favorite]
From a certain perspective, all human geography is pretty arbitrary. :)
posted by kevinbelt at 12:20 PM on August 16, 2019 [1 favorite]
For an article so considered with precision, I found it a little odd that it didn't cleanly differentiate between zip codes and ZCTAs. I mean, it correctly identifies that zip codes aren't actually areas but rather routes. But it doesn't mention all the other ways that ZCTAs can differ from zip codes (e.g.: there is no ZCTA for zip code 98030; zip code 98030 is aggregated into ZCTA 98031). Consider this article for more details on that difference.
posted by mhum at 12:28 PM on August 16, 2019 [3 favorites]
posted by mhum at 12:28 PM on August 16, 2019 [3 favorites]
While we're considering options for aggregating data spatially in the US, another set of very useful polygons are political groupings. Voting precincts, congressional districts (both state and federal), etc. Unfortunately there's no great central source for this data and it changes frequently. One very useful open data collection is Election GeoData by (MeFi's own) Kelso and Migurski. There's also OpenPrecincts.org, OpenElections.net, and some work related to the PlanScore districting tool.
I agree with entropone's point that zip codes are very convenient and available. Certainly no ordinary person knows their census tract or electoral precinct number. I see Carto's article and others as a push towards encouraging data scientists to do better. If you have a person's full address you can geocode that to a lat/lon and aggregate it into a census block or H3 polygon or whatever just as easily as a zipcode. If all you have in your data source is zipcode level already though, well, you're out of luck. At least be aware of the bizarre biases that postal aggregation introduces.
posted by Nelson at 1:01 PM on August 16, 2019 [3 favorites]
I agree with entropone's point that zip codes are very convenient and available. Certainly no ordinary person knows their census tract or electoral precinct number. I see Carto's article and others as a push towards encouraging data scientists to do better. If you have a person's full address you can geocode that to a lat/lon and aggregate it into a census block or H3 polygon or whatever just as easily as a zipcode. If all you have in your data source is zipcode level already though, well, you're out of luck. At least be aware of the bizarre biases that postal aggregation introduces.
posted by Nelson at 1:01 PM on August 16, 2019 [3 favorites]
Proof: https://www.zip-codes.com/zip-code/20252/zip-code-20252.asp
posted by 922257033c4a0f3cecdbd819a46d626999d1af4a at 3:15 PM on August 16, 2019
posted by 922257033c4a0f3cecdbd819a46d626999d1af4a at 3:15 PM on August 16, 2019
Seems like most weather apps I’ve used use zip codes for location. You can sometimes put an address in, but that’ll either drop you in a zip code, or worse, a whole city/town.
My zip code includes both desert and alpine climates.
posted by shorstenbach at 3:19 PM on August 16, 2019 [2 favorites]
My zip code includes both desert and alpine climates.
posted by shorstenbach at 3:19 PM on August 16, 2019 [2 favorites]
Ya Canada's Postal codes are pretty granular generally; too granular really. It is often pretty easy to figure out exactly who a particular piece of data in an anonymized dataset is representing if you are given a postal code plus some demographic data. Like we're the only family in my postal code with a single child (all others either multiple kids or none). The different postal code across the street only has a single home whose occupants are both over 65. A lot of postal codes represent only a few single family homes.
The problem would exist with small communities who all have a single postal code but even then that code only represents maybe a 1000 people often spread out over a huge chunk of land.
It's not perfect but it is much better than the US system in this regard.
And the example the author shows of Toronto is just weird to be complaining about. It's a single half block containing a school, a church, a corner store and a few dozen housing units. There might be a wide range of income levels in that postal code but how the heck would you otherwise group the area by area?
posted by Mitheral at 3:35 PM on August 16, 2019
The problem would exist with small communities who all have a single postal code but even then that code only represents maybe a 1000 people often spread out over a huge chunk of land.
It's not perfect but it is much better than the US system in this regard.
And the example the author shows of Toronto is just weird to be complaining about. It's a single half block containing a school, a church, a corner store and a few dozen housing units. There might be a wide range of income levels in that postal code but how the heck would you otherwise group the area by area?
posted by Mitheral at 3:35 PM on August 16, 2019
An economic development director I know who works with rural counties mentioned that the data for one county she works with is skewed, and they have a hard time getting economic development funds and grants for the entire county.
Because the county has exactly one multi-billionaire who lives there.
This is insane to me because this is like the very first example teachers will pull up in 4th grade when discussing the different between mean, median, and mode.
Mean income is completely meaningless when one person is making like $5,000,000,000 and the other like 9000 are making around $12,000 annually.
(The mean in that example is over $500,000 whereas the median is $12,000--a slight discrepancy.)
She knew exactly what I was talking about, but swore up and down that whatever arcane ways the federal govt has for determining eligibility, that one multi-billionaire really did put a giant thumb on the scales.
FWIW.
posted by flug at 7:53 PM on August 16, 2019 [5 favorites]
Because the county has exactly one multi-billionaire who lives there.
This is insane to me because this is like the very first example teachers will pull up in 4th grade when discussing the different between mean, median, and mode.
Mean income is completely meaningless when one person is making like $5,000,000,000 and the other like 9000 are making around $12,000 annually.
(The mean in that example is over $500,000 whereas the median is $12,000--a slight discrepancy.)
She knew exactly what I was talking about, but swore up and down that whatever arcane ways the federal govt has for determining eligibility, that one multi-billionaire really did put a giant thumb on the scales.
FWIW.
posted by flug at 7:53 PM on August 16, 2019 [5 favorites]
Justicemap.org
Bibliography for Dr Bullard
Bullard, Robert D., Paul Mohai, Robin Saha, and Beverly Wright, “Toxic Wastes and Race at Twenty: Why Race Still Matters After All of These Years,” Lewis & Clark Environmental LawJournal 38 (2): 2008
posted by eustatic at 10:30 PM on August 16, 2019
Bibliography for Dr Bullard
Bullard, Robert D., Paul Mohai, Robin Saha, and Beverly Wright, “Toxic Wastes and Race at Twenty: Why Race Still Matters After All of These Years,” Lewis & Clark Environmental LawJournal 38 (2): 2008
posted by eustatic at 10:30 PM on August 16, 2019
I did a deep dive on this last year after finding the perfect example; the River Oaks neighborhood in Houston. It's a famously wealthy area, zip code 77019. But that zip code is shared with a neighborhood to the east which is significantly less wealthy. --
Nelson
You got me thinking. 94025 includes Sand Hill Road, a road in Menlo Park, CA where many of Silicon Valley's multi-billion dollar VC firms are, where Apple, Google, Facebook, Linkedin, Instagram, and, well, you name it, got their first funding.
It also includes East Menlo Park, which at one time was one of the poorest, most crime ridden areas of the SF Bay Area. I'm sure you'd get some pretty weird data in your study if you included that zip code.
posted by eye of newt at 10:55 PM on August 16, 2019
Nelson
You got me thinking. 94025 includes Sand Hill Road, a road in Menlo Park, CA where many of Silicon Valley's multi-billion dollar VC firms are, where Apple, Google, Facebook, Linkedin, Instagram, and, well, you name it, got their first funding.
It also includes East Menlo Park, which at one time was one of the poorest, most crime ridden areas of the SF Bay Area. I'm sure you'd get some pretty weird data in your study if you included that zip code.
posted by eye of newt at 10:55 PM on August 16, 2019
The right answer for many applications, as this article notes, is census tracts named by FIPS codes. These are designed by the census to be demographically consistent
I don't think "designed to be demographically consistent" is a good way to describe census tracts. Mainly, tracts are designed to have roughly equal populations (unlike ZIP codes).
They also are supposed to have boundaries that should follow specific types of geographic features that do not change frequently. However there are circumstances where participants in the PSAP program may elect to "hold" tract boundaries in order to make them consistent from Census to Census or to coincide with other locally meaningful boundaries (for example neighborhoods).
This Federal Register notice is a great source of info on Census Tracts – it not only describes the criteria for the upcoming 2020 Census Tracts, but it also gives some background and explanation of the changes throughout the years.
(thanks to Mrs. exogenous for this - it has been a big part of her job for years)
posted by exogenous at 6:22 AM on August 17, 2019 [3 favorites]
I don't think "designed to be demographically consistent" is a good way to describe census tracts. Mainly, tracts are designed to have roughly equal populations (unlike ZIP codes).
They also are supposed to have boundaries that should follow specific types of geographic features that do not change frequently. However there are circumstances where participants in the PSAP program may elect to "hold" tract boundaries in order to make them consistent from Census to Census or to coincide with other locally meaningful boundaries (for example neighborhoods).
This Federal Register notice is a great source of info on Census Tracts – it not only describes the criteria for the upcoming 2020 Census Tracts, but it also gives some background and explanation of the changes throughout the years.
(thanks to Mrs. exogenous for this - it has been a big part of her job for years)
posted by exogenous at 6:22 AM on August 17, 2019 [3 favorites]
For some purposes Zip code level data is better and more cost effective than guessing, random selection, hearsay, and hunches.
posted by Homer42 at 6:22 AM on August 17, 2019 [1 favorite]
posted by Homer42 at 6:22 AM on August 17, 2019 [1 favorite]
I'm surprised this didn't come up. Ecological bias (or fallacy) is well known in epidemiologic research and is devilishly hard to control for. It's like a circular problem: unless you know the underlying causal model that generates the data, you can't correct for it fully, and without correcting for it, it's impossible to get the right causal model.
posted by Mental Wimp at 1:52 PM on August 17, 2019
posted by Mental Wimp at 1:52 PM on August 17, 2019
"Ya Canada's Postal codes are pretty granular generally; too granular really."
True that. I'm asked for my postal code by merchants sometimes. I just give a hearty laugh. They tend to be literally less than a dozen houses. Never give your postal code to someone you wouldn't give your full address to. Also: don't give your full address to someone unless you want them to send you physical mail.
If you don't want to have a conversation with someone about this and want be pleasant to merchants, memorize another postal/zip code and rattle that off instead.
posted by el io at 4:38 PM on August 17, 2019
True that. I'm asked for my postal code by merchants sometimes. I just give a hearty laugh. They tend to be literally less than a dozen houses. Never give your postal code to someone you wouldn't give your full address to. Also: don't give your full address to someone unless you want them to send you physical mail.
If you don't want to have a conversation with someone about this and want be pleasant to merchants, memorize another postal/zip code and rattle that off instead.
posted by el io at 4:38 PM on August 17, 2019
H0H 0H0 - If you pronounce the 0 as zero rather than oh they generally won't get it.
posted by Mitheral at 7:34 PM on August 17, 2019
posted by Mitheral at 7:34 PM on August 17, 2019
I'm asked for my postal code by merchants sometimes. I just give a hearty laugh.
Surely you live at 30 Yonge St, Toronto, ON M5E 1X8? When you're not living at 1060 W. Addison in Chicago?
posted by GCU Sweet and Full of Grace at 8:26 PM on August 17, 2019
Surely you live at 30 Yonge St, Toronto, ON M5E 1X8? When you're not living at 1060 W. Addison in Chicago?
posted by GCU Sweet and Full of Grace at 8:26 PM on August 17, 2019
For whatever reason, Houston never opted to give the Astrodome its own Zip code. It used to just be the Astrodome and Astro World so it was fine. Alas, the latter was turned into apartments thirty years ago.
So now, there’s an entire complex of football and rodeo buildings next to—and in the same code as—a half-mile radius of random, but geographically proximate, apartment buildings.
This would be fine if hadn’t been for the Texans’ marketing department. They have a long running campaign where the stadium is fictionally located in ‘Gridiron, TX 77054’.
Unfortunately, that somehow got into some business’ database. Which really isn’t cool for the apartment residents trying to assert what city they live in to random faceless companies. Just, give the really large sports complex its own Zip code y’all.
Also don’t get me started on the fact that my very large workplace does have its own Zip code but none of the business datasets (the ones that power the ‘find the closest X’ on websites) ever think it exists. I think it’s listed in some way to mean ‘don’t count it as people live here’ for business purposes. Which, hah, people do actually.
In short, Zip codes are the bane of my existence.
posted by librarylis at 9:18 PM on August 17, 2019 [1 favorite]
So now, there’s an entire complex of football and rodeo buildings next to—and in the same code as—a half-mile radius of random, but geographically proximate, apartment buildings.
This would be fine if hadn’t been for the Texans’ marketing department. They have a long running campaign where the stadium is fictionally located in ‘Gridiron, TX 77054’.
Unfortunately, that somehow got into some business’ database. Which really isn’t cool for the apartment residents trying to assert what city they live in to random faceless companies. Just, give the really large sports complex its own Zip code y’all.
Also don’t get me started on the fact that my very large workplace does have its own Zip code but none of the business datasets (the ones that power the ‘find the closest X’ on websites) ever think it exists. I think it’s listed in some way to mean ‘don’t count it as people live here’ for business purposes. Which, hah, people do actually.
In short, Zip codes are the bane of my existence.
posted by librarylis at 9:18 PM on August 17, 2019 [1 favorite]
So along with falsehoods programmers believe about Names, falsehoods programmers believe about time, falsehoods programmers believe about Phone Numbers and the recent falsehoods programmers believe about Null we should have a list of falsehoods programmers believe about zip/postal codes.
Github has a collected a bunch of these.
posted by Mitheral at 11:04 PM on August 17, 2019 [1 favorite]
Github has a collected a bunch of these.
posted by Mitheral at 11:04 PM on August 17, 2019 [1 favorite]
Falsehoods programmers believe about addresses has some good ZIP Code and postal code content.
posted by Nelson at 8:10 AM on August 18, 2019 [1 favorite]
posted by Nelson at 8:10 AM on August 18, 2019 [1 favorite]
« Older Syndicalism In The USA | Super Sad True Chef Story Newer »
This thread has been archived and is closed to new comments
posted by msbutah at 9:51 AM on August 16, 2019 [3 favorites]