Open Platform
March 10, 2009 9:31 PM Subscribe
Somewhat quietly within the past couple weeks, two major newspapers, on each side of the Atlantic, have opened up their data and content APIs. Last month, on their Open blog, the New York Times introduced their Developer Network. Then just yesterday, on their DataBlog and OpenPlatformBlog, the Guardian launched Open Platform.
Insiders at the Guardian are talking about the Data Store and the Content API. Even Members of Parliament are duly impressed. The Times will be at SXSW this week to talk about opening up as an information platform. The Information Age is truly coming of age.
Insiders at the Guardian are talking about the Data Store and the Content API. Even Members of Parliament are duly impressed. The Times will be at SXSW this week to talk about opening up as an information platform. The Information Age is truly coming of age.
i'm not sure what it means for revenue, but developers like me, or developers with more tact and tenacity than me, can access their data for free and create cool info-graphics when we get bored or otherwise.
posted by localhuman at 10:25 PM on March 10, 2009
posted by localhuman at 10:25 PM on March 10, 2009
"How might the Times’ APIs be used? Well, one of them provides access to all of the newspaper’s movie reviews. Wouldn’t it be helpful, when making you’re next Netflix selection, to see the latest recommendations by A.O. Scott without navigating to the Times? Netflix just released its own API, so this application now, blissfully, exists.
There may also be a business model here: Marc Frons, chief technology officer at the Times Co., has said they plan to charge for commercial uses of their APIs. So if Amazon wanted to add the Times best seller lists to its site, customers might benefit from the additional information, and the Times could get paid for its work." - cite
posted by netbros at 10:35 PM on March 10, 2009
There may also be a business model here: Marc Frons, chief technology officer at the Times Co., has said they plan to charge for commercial uses of their APIs. So if Amazon wanted to add the Times best seller lists to its site, customers might benefit from the additional information, and the Times could get paid for its work." - cite
posted by netbros at 10:35 PM on March 10, 2009
"All the New York Times is doing is using its article database in the same way that Google uses its map database, or the Google Earth satellite-imagery database — as a foundation upon which other things can be built. The Times deserves kudos for pursuing such a open model rather than locking its articles up and trying to charge people for every view. I have no doubt that it will benefit far more from such an approach in the long run than would ever be possible with a pay-per-view strategy." - Matthew Ingram, Seeking Alpha
posted by netbros at 10:42 PM on March 10, 2009
posted by netbros at 10:42 PM on March 10, 2009
This is an important development.
posted by Samuel Farrow at 10:44 PM on March 10, 2009
posted by Samuel Farrow at 10:44 PM on March 10, 2009
NPR's API has been used for useful purposes.
Newspapers everywhere are still scrambling to adapt to the web. This graphic shows some of the other web stuff they're doing. Anybody remember CRAYON.net? When I first saw CRAYON in 1995 I knew that newspapers would have to change forever.
posted by twoleftfeet at 10:55 PM on March 10, 2009
Newspapers everywhere are still scrambling to adapt to the web. This graphic shows some of the other web stuff they're doing. Anybody remember CRAYON.net? When I first saw CRAYON in 1995 I knew that newspapers would have to change forever.
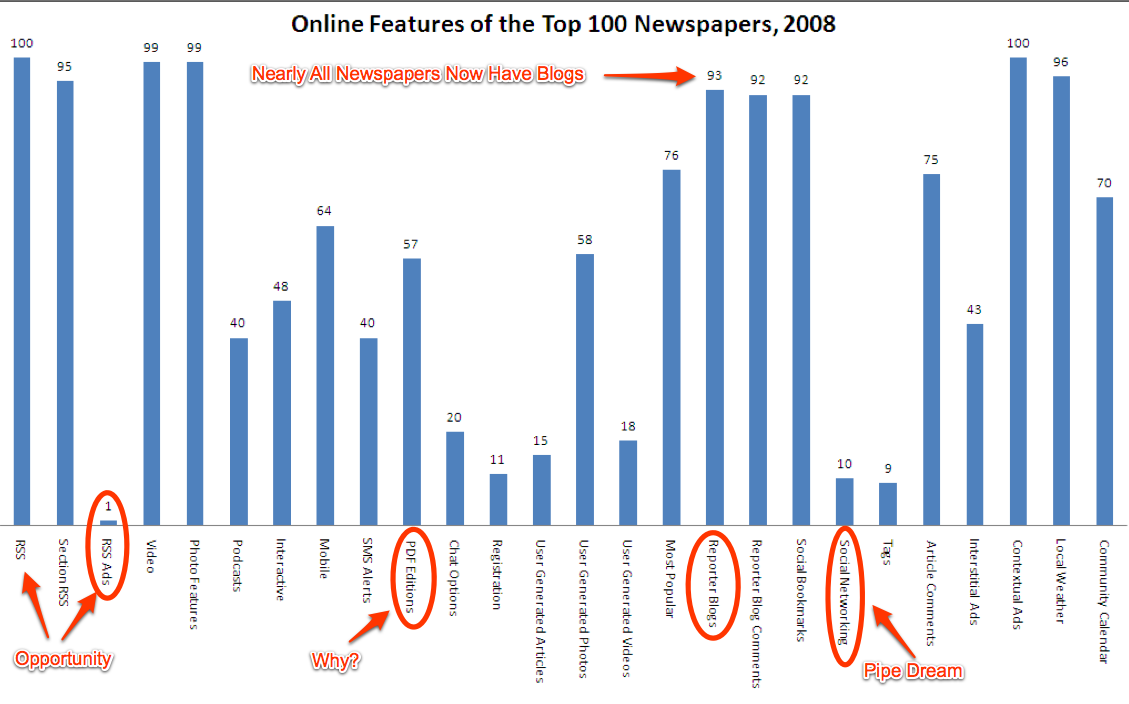{kind=link}
posted by twoleftfeet at 10:55 PM on March 10, 2009
It's certainly a step forward from the days when the NY Times wasn't even available on NEXUS. (Probably still isn't, who uses NEXUS anymore anyway?)
posted by StickyCarpet at 11:02 PM on March 10, 2009
posted by StickyCarpet at 11:02 PM on March 10, 2009
I question whether it's too little, far too late, but at least they seem to be heading in the right general direction — or at least in a direction that's not obviously wrong.
At least we'll get some cool info-graphics out of it, either way.
posted by Kadin2048 at 11:09 PM on March 10, 2009
At least we'll get some cool info-graphics out of it, either way.
posted by Kadin2048 at 11:09 PM on March 10, 2009
Well, that's all very well, but if, as Matthew Ingram says in the quote above, the NY Times doesn't make money by charging for access, then how are they going to make money?
Ads? The problem with online ads is that the inventory just keeps on getting bigger and bigger and bigger, pushing the CPMs and the sell-through rates down.
If the NY Times (and others) doesn't charge for access to their incredibly valuable archive I'd say they're crazy.
posted by awfurby at 12:26 AM on March 11, 2009
Ads? The problem with online ads is that the inventory just keeps on getting bigger and bigger and bigger, pushing the CPMs and the sell-through rates down.
If the NY Times (and others) doesn't charge for access to their incredibly valuable archive I'd say they're crazy.
posted by awfurby at 12:26 AM on March 11, 2009
Worth noting that the Guardian is owned by a non-profit foundation, so it has slightly different revenue goals than a privately owned newspaper.
posted by atrazine at 12:37 AM on March 11, 2009
posted by atrazine at 12:37 AM on March 11, 2009
I like this. I'd really like if they could find a way to offer the same API data via Atom as well (a quick look seems to indicate this is possible) but the direction seems good, in any case. A possible business case similar to the Amazon cite: serving this (or richer) data to large-scale, world-popular aggregators and using it to share revenue - iTunes-like.
posted by massless at 2:18 AM on March 11, 2009
posted by massless at 2:18 AM on March 11, 2009
who uses NEXUS anymore anyway?
travelers. ;)
NEXIS still gets used quite a bit, especially by reporters for real newspapers with real budgets for news gathering and background analysis on stories.
posted by caddis at 4:13 AM on March 11, 2009 [1 favorite]
travelers. ;)
NEXIS still gets used quite a bit, especially by reporters for real newspapers with real budgets for news gathering and background analysis on stories.
posted by caddis at 4:13 AM on March 11, 2009 [1 favorite]
Kadin2048: "I question whether it's too little, far too late,"
Or conversely it suggests we have a long way to go yet. First NYT, next the Federal Government. The era of open data is just starting we probably haven't seen nothing yet. Imagine your electric company feeding open data on a per-household electric socket basis, how that would create new devices and new industries.
posted by stbalbach at 5:38 AM on March 11, 2009
Or conversely it suggests we have a long way to go yet. First NYT, next the Federal Government. The era of open data is just starting we probably haven't seen nothing yet. Imagine your electric company feeding open data on a per-household electric socket basis, how that would create new devices and new industries.
posted by stbalbach at 5:38 AM on March 11, 2009
awfurby: "If the NY Times (and others) doesn't charge for access to their incredibly valuable archive I'd say they're crazy."
It's unclear how much NYT is giving away. The details page shows what you can retrieve. There do seem to be hard limits in quantity and dates and stuff. I seriously doubt they are giving away free access to the full archives, which they currently charge for.
posted by stbalbach at 5:41 AM on March 11, 2009
It's unclear how much NYT is giving away. The details page shows what you can retrieve. There do seem to be hard limits in quantity and dates and stuff. I seriously doubt they are giving away free access to the full archives, which they currently charge for.
posted by stbalbach at 5:41 AM on March 11, 2009
Imagine your electric company feeding open data on a per-household electric socket basis.
My electric company most certainly cannot identify individual sockets in my house, only the total consumption of the home at the meter.
That said, I wish sockets themselves were query-able on my little coat-hanger and paper-clip network.
posted by rokusan at 5:56 AM on March 11, 2009
My electric company most certainly cannot identify individual sockets in my house, only the total consumption of the home at the meter.
That said, I wish sockets themselves were query-able on my little coat-hanger and paper-clip network.
posted by rokusan at 5:56 AM on March 11, 2009
This is a good sign, in general. Queryable data is always good, and those who guard their data fiercely are almost always the web's least useful firms anyway.
The problem, of course, will be that data will come in 1000 custom formats, XML be damned.
posted by rokusan at 5:57 AM on March 11, 2009
The problem, of course, will be that data will come in 1000 custom formats, XML be damned.
posted by rokusan at 5:57 AM on March 11, 2009
I'm not sure if The Guardian service can be described as "open".
posted by cedar at 7:26 AM on March 11, 2009
API key approvals will be granted on a very limited basis, so please don't be offended if we fail to reply to you or don't approve your request in the short term. [Source]Maybe this will change when the service is out of beta but for the moment it is looking like a gated community.
posted by cedar at 7:26 AM on March 11, 2009
The era of open data is just starting we probably haven't seen nothing yet. Imagine your electric company feeding open data on a per-household electric socket basis, how that would create new devices and new industries.
Oh I agree with you on this being the beginning of open data; I question whether it's perhaps too late to save the newspapers with it, though.
I think "open data" and web services are going to be one of those things that we look back on and wonder why it didn't happen long before it did. Most of the pieces that are being used for information sharing today have been around for a while; IBM developed GML in the late 60s, and SGML in the 80s (IIRC), precisely to facilitate this sort of data interchange, and most of the other components of the modern web service / application server stack have roots going back at least that far. It seems like it's just taken until very recently to put all the pieces together in a useful, coherent, and well-standardized way.
posted by Kadin2048 at 11:02 AM on March 12, 2009
Oh I agree with you on this being the beginning of open data; I question whether it's perhaps too late to save the newspapers with it, though.
I think "open data" and web services are going to be one of those things that we look back on and wonder why it didn't happen long before it did. Most of the pieces that are being used for information sharing today have been around for a while; IBM developed GML in the late 60s, and SGML in the 80s (IIRC), precisely to facilitate this sort of data interchange, and most of the other components of the modern web service / application server stack have roots going back at least that far. It seems like it's just taken until very recently to put all the pieces together in a useful, coherent, and well-standardized way.
posted by Kadin2048 at 11:02 AM on March 12, 2009
« Older Breaking Lincoln News | Roberto Kusterle Newer »
This thread has been archived and is closed to new comments
Sorry, but I'm a bit slow.
posted by KokuRyu at 10:14 PM on March 10, 2009